銷售熱線:188 2384 2885
銷售熱線:188 2384 2885
基于分段擬合的機床大尺寸工作臺熱誤差補償模型
0 前言
在影響零件加工精度的因素中,機床熱誤差是影響加工精度的主要原因之一,在精密機床加工中由于熱因素造成的加工誤差可以占到60% ~70%。為降低或消除機床熱誤差對加工精度的影響,科研人員進行了大量廣泛深入的研究,目前主要有兩種減小熱誤差的途徑:硬件消除法和軟件補償法。硬件消除法主要是通過熱結構對稱設計、預拉伸和采用低熱膨脹系數的材料來實現,硬件消除法缺點是成本較高。軟件補償法是通過建立能夠反映機床溫度與熱誤差關系的數學模型,在補償時用模型產生的預測值來抵消機床因溫度變化產生的誤差,以此達到消除熱誤差的目的。軟件補償法的優點是,實現成本較低且無須對現有機床進行大的改造,應用簡便易于推廣。軟件補償法的關鍵是建立能夠準確反映機床溫度與誤差之間的數學模型,這也是目前熱誤差補償研究工作的熱點和難點。補償模型分為離線靜態模型和在線動態實時模型,常見靜態補償模型如:多元統計回歸、最小二乘支持向量機、灰色系統理論、神經網絡等。如果機床使用環境和建模環境相近,靜態熱誤差模型能夠取得較好的預測效果,但是當機床使用環境和建模環境相差比較大或環境溫度和工況變化比較大時,模型預測精度會嚴重受到影響。為了提高熱誤差補償模型的精度和適應能力,研究者提出了實時在線動態補償模型,在線模型能夠根據加工狀況、環境溫度等的變化實時調整模型參數,使模型能跟蹤機床熱誤差的變化,所以在線動態模型具有更高的預測精度和適應能力。
以上建模方法為熱誤差補償提供了有力工具,且在試驗中取得了良好效果。機床部件受熱不僅會產生熱膨脹伸長,還會產生彎曲變形。如絲杠螺母在傳動過程中由于摩擦作用產生熱,文獻分析了絲杠熱彈性效應導致對工作臺縱向定位精度的影響。文獻提出一種幾何誤差和熱誤差建模方法,對熱誤差分離后,建立了不同位置不同溫度下的熱誤差補償模型,提高了工作臺定位精度。實際工作中絲杠螺母摩擦熱一部分傳入絲杠,還有一部分傳入工作臺,傳入工作臺的這部分熱,分布不均勻將會導致工作臺熱變形。現有文獻在熱誤差建模時對工作臺熱變形考慮較少,本文在三坐標銑床上通過試驗發現絲杠螺母傳入工作臺的熱導致工作臺兩側產生翹曲,為了對工作臺熱變形造成的熱誤差進行補償,先建立工作臺不同位置熱誤差模型,再對工作臺各點模型預測值進行分段擬合,實現對工作臺任意位置的熱誤差預測。為了增加模型的預測精度和適應能力,通過聚類分析和逐步回歸尋找最佳測溫點,采用粒子群優化實時辨識動態模型參數,提高了模型魯棒性和預測精度。
1 溫度測點的選取及建模方法
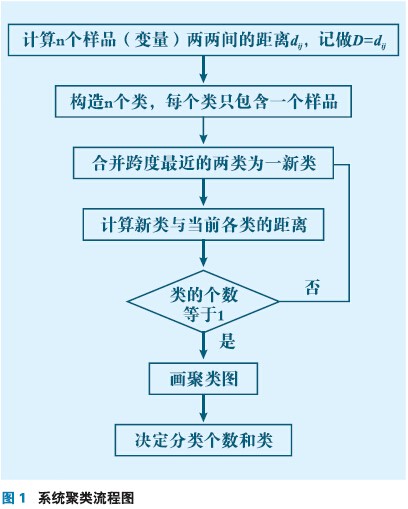
在選取溫度測點時認為不同位置溫度點只要溫度變化規律相似,對熱誤差模型的作用就相似,在建模時可以從相似的測點中選取一個作為代表變量,機床熱誤差模型可以用幾個關鍵的溫度點來表征。基于上述假設,可以在機床上布置大量傳感器,然后根據每點的溫度變化規律進行分類,再從每個分類中選取一個溫度變量進行熱誤差建模。這樣就減小了溫度測點選取的盲目性,且能利用較少的溫度變量建立熱誤差模型。本研究先用聚類分析方法對溫度變量進行分類,再利用逐步回歸選取與熱誤差變化最相關的溫度測點,然后根據選取的測點作為輸入變量,建立差分熱誤差模型。
(1)聚類分析方法。聚類分析是一種分類方法,它能將一批樣品或變量,按照它們在某種評定標準上的相似程度或遠近進行分類,目的是使同類內對象的同質性最大和類與類之間的對象差異性最大。為了對樣品(變量)進行分類,一般采用兩種方法:①相似系數法,性質越相似或越接近的它們相似系數為1,彼此無關的相似系數接近0,相似的樣品(變量)歸為一類;② 距離法,把樣品看做空間中的一個點,然后定義距離,距離近的點歸為一類。常用的分類方法有5種:即最短距離法、最長距離法、類平均法、重心法、離差平方和法。
這5種聚類法的計算步驟一樣,不同的是距離的定義方法,當采用歐氏距離時5種方法有統一的遞推公式中,
Dkr表示類Gk與類Gr之間的距離,
(2)逐步回歸原理。逐步回歸原理是在建立因變量和自變量回歸模型時,自變量逐次引入,每引入一個自變量,對進入的變量進行逐個檢驗,當原引入的變量由于后面變量的進入而變得不再顯著時,就將其剔除。引入或剔除一個變量稱為逐步回歸的一步,每步都要進行F 檢驗,以確保新引入變量前,回歸方程中只包含顯著地變量。這個過程反復進行,直到既無新的變量進入回歸方程也無變量可剔除,計算停止得到逐步回歸下的最優方程。
1.2 建模原理
(1)差分方程模型。差分方程輸出值不僅與當前的輸入值有關還和歷史輸入有關,而熱誤差的變化也與歷史熱輸入大小有關,因此采用差分結構描述熱膨脹更符合其物理意義。差分方程建模屬于動態建模,差分方程形式如式(2)所示
式中,
(2)模型參數實時辨識方法。采用粒子群優化算法,根據實時反饋的溫度和熱誤差數據對模型參數進行辨識。
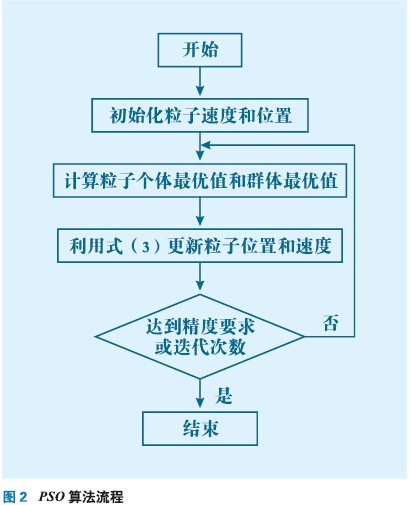
基于粒子群優化算法辨識原理:粒子群優化算法(Particle swarm optimization, PSO)是一種群體優化算法,來源于人工生命和演化計算理論。基本原理如下:求解問題時,每個粒子都隨機設置初始位置和初始速度,初始位置表示在解空間中的一組解,速度表示搜索解空間的快慢。如在D 維空間中搜索,每個粒子就可以用D 維矢量表示,第i 個粒子的位置表示為x=(xi1,xi2,…,xiD),速度表示為vi= (vi1,vi2,…,viD)。每個粒子適應度的優劣由適應度函數F 評價,粒子經過一次迭代,搜索到的個體最優值: pi= (pi1,pi2,…,piD),群體最優值:pg = (pg1,pg2,…,pgD),然后再跟據式(3)更新粒子位置和速度
式中,
式中,y0(t)為實際系統輸出;
2 熱誤差試驗
2.1 試驗安排
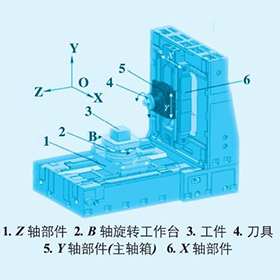
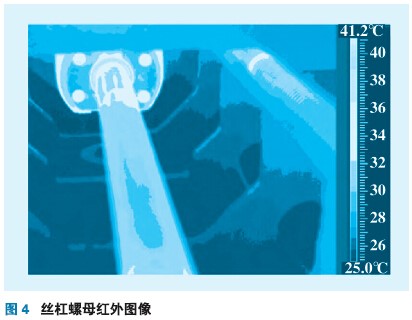
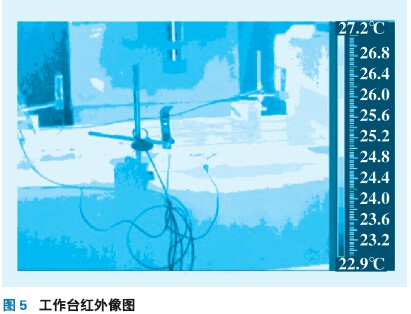
本試驗以三坐標銑床工作臺為研究對象,x 軸以指令G00快速移動時,測量在工作臺長度方向最左、中、最右三個點縱向熱變形(工作臺尺寸:長900 mm,寬410 mm)。傳感器安裝如圖3所示,T1放置在絲杠螺母附近;T2,T3 放置在伺服電機減速器上;T4放置在絲杠軸承座上;T5,T6放置在工作臺中間;T7測量環境溫度。電渦流位移傳感器分別安裝在工作臺最左、中、最右三個位置。工作臺x軸行程0~500 mm;往復移動速度(以指令G00快速運行);第一個升溫階段快速運行2.5h,停止2.5h;第二個升溫階段運行(第一階段速度的70%)2.5h,停止2.5 h;每隔5 min 對測點溫度和熱誤差進行一次采樣。工作臺運行1h后的絲杠螺母和工作臺的紅外圖像如圖4、5所示;溫度和熱誤差測量數據如圖6、7 所示。
圖4、5 表明,工作臺運動時絲杠螺母處溫度比較高,局部可以達到40℃,由此傳入工作臺使工作臺表面中間部位溫度高,兩側溫度低,工作臺上表面最高溫度27 ℃,說明從絲杠螺母處到工作臺上表面存在溫度梯度。
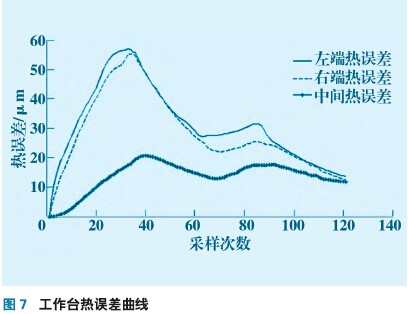
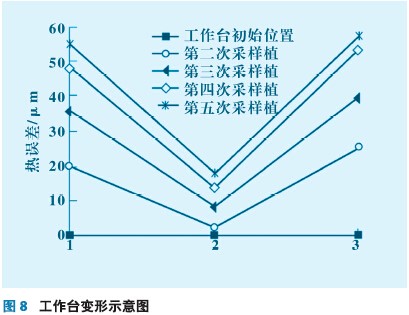
試驗測量的溫度和熱誤差曲線圖6、7所示。從圖6和圖7看出,當測點溫度隨機床工作狀態變化時,工作臺縱向誤差也隨之發生改變,而且工作臺兩側和中間熱誤差變形量不同,也就是說工作臺熱變形后呈“凹狀”。根據這一現象,對機床縱向加工誤差進行補償時,不能采取固定值,而應該隨著工作臺的位置不同而采取不同的補償量使之適應工作臺面隨溫度和位置的變化。整個工作臺隨著受熱變形規律及變形量可由圖8表示。從圖8中看出工作臺在熱變形時,兩側的熱變形量要大于中間的熱膨脹量且兩側變形速度大于中間位置,導致工作臺兩側翹曲,使臺面呈凹狀。
為了驗證工作臺在連續往復工作時由于熱變形呈“凹狀”這一現象是否符合物理原理,采用有限元法進行驗證(由于有限元仿真邊界條件不可能完全符合實際工作條件,仿真數據可能和實測數據有差異,但是結果能夠反映該變化的趨勢,所以可以利用有限元法進行驗證這種現象),如圖9所示。有限元熱變形圖是在絲杠螺母處給定攝氏溫度60 ℃,仿真時間為20min的結果。從圖9上能明顯看出工作臺兩側發生翹曲,與試驗結果得到的現象相吻合,說明試驗觀察到的現象是可能發生的。
3 溫度測點選取及熱誤差建模
3.1 最佳溫度測點的選取
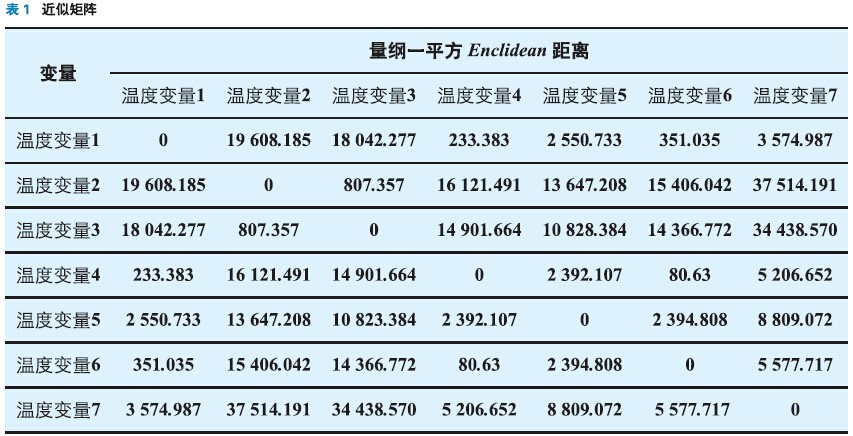
對7個溫度變量進行系統聚類分析,采用最短距離法,平方Euclidean距離,計算出兩兩變量的近似矩陣,如表1所示。
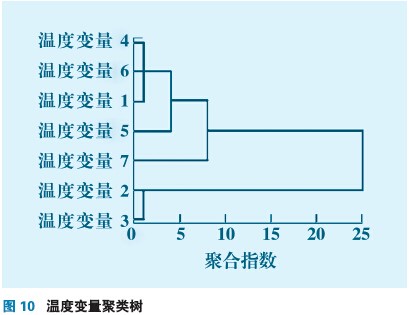
根據計算的近似系數,按圖1流程得到圖10所示聚類樹,縱坐標是變量個數,橫坐標聚合指數是將實際的距離按照比例調整到0~25的范圍內。7個溫度變量按照四類進行選取,從每一類中選取一個變量得到T1、T5、T7、T2四個為基本待選變量。
方程復相關系數R = 87%,各變量因子顯著水平遠小于0.05,說明各自變量與因變量線性相關程度顯著,由此選取和熱誤差有顯著關系的溫度變量為T1和T2。
3.2 差分方程階次的確定
確定方程階次是采用從1 階逐次遞增,同時考察模型預測值與測量值殘差平方和的大小來確定,當增加階次殘差平方和變化不明顯時,采用此時階次值。根據上面方法并考慮運算簡單性,確定差分方程為二階
由于工作臺兩側和中間的變形量不一樣,因此需要3個模型分別對工作臺左側、中間和右側熱誤差進行預測。如果工作臺左右兩側熱誤差相差很小,可以共用1個模型進行預測。
3.3 參數模型實時辨識
確定熱誤差模型結構后,采用粒子群優化算法對模型參數進行辨識。對熱誤差模型參數辨識并不是每個反饋周期都進行,而是當模型輸出值和熱誤差反饋值殘差超過一定范圍時,再啟動辨識算法對模型參數進行辨識更新。辨識的輸入數據為最近的10次采樣數據,使熱誤差模型始終反映機床最新的工作狀態。
3.4 擬合模型的建立
設EL(t),EM(t),ER(t)分別為工作臺左側、中間和右側在t 時刻的熱誤差模型預測值,為對工作臺左半部分行熱誤差預測,利用EL(t)和EM(t)進行直線擬合得到擬合公式(6),由于不同時刻EL(t)和EM(t)取值不同,所以a和b是時變系數
式中,
4 熱誤差建模結果及分析
4.1 單點模型建模結果及分析
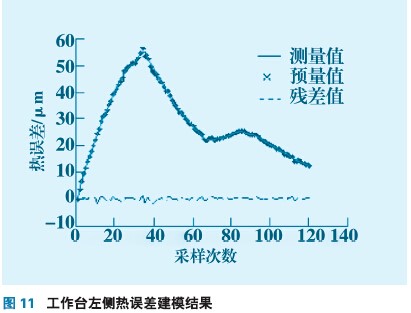
由于工作臺中間熱誤差模型和兩側熱誤差模型結構形式相同,辨識算法也一樣,在此只給出工作臺左側熱誤差模型驗證結果。采用粒子群優化參數辨識工作臺左側模型參數,辨識結果如圖11所示。
通過圖11看出,在第一個升溫階段模型預測值與測量值符合較好殘差很小,因為此階段工況單一,熱誤差模型能夠進行較好的預測;當溫度開始下降時,在第38個采樣時刻出現一次波動,說明熱誤差模型參數和機床狀態不匹配,殘差超出限定值需要更新模型參數,更新模型參數后直到下一個升溫過程,預測值效果良好,殘差值較小。在第68個采樣時刻殘差又出現一次波動,模型進行參數更新,使熱誤差模型隨著機床熱狀態的變化而實時調整。說明該算法有一定的自適應能力,能夠根據殘差的變化實時更新模型參數,模型預測結果如表2所示。
4.2 分段擬合模型驗證及分析
通過上述辨識過程得到工作臺中間和兩側的單點熱誤差模型,要對工作臺整體范圍進行熱誤差補償,還需要進一步對熱誤差模型進行擴展,因為上述熱誤差模型只是描述工作臺三個位置的熱誤差狀態。為了對整個臺面的熱誤差進行補償,對每一時刻預測值得到的左、中和右三個數值進行分段擬合得到擬合公式,在補償時由分段擬合公式得到工作臺任意位置的熱誤差量,這樣就可以做到對整個工作臺的任意位置進行補償。為驗證這一過程,在工作臺中間傳感器和最左端傳感器中間處再放置一個位移傳感器,用來測量該位置的熱誤差值作為驗證值。預測模型采用最左端和中間熱誤差模型的預測值做直線擬合,然后根據得到的直線模型對中間點進行預測。直線分段擬合模型預測值與測量值進行比較,結果如圖12所示,殘差指標如表3所示。
從圖12和表3看出,采用兩點直線擬合公式對中間熱進行預測,效果良好,采用直線分段擬合方法能夠實現對工作臺任意位置的縱向熱誤差精確預測。根據此原理很容易建立工作臺右側部分的直線分段擬合模型。
5 結論
1.1 溫度測點的選取方法
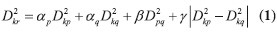
Gr是Gq和Gp合并后形成的新類。
αp,αq, β, γ對不同方法有不同的取值,具體取值參見文獻。采用系統聚類法進行分類的流程如圖1所示。
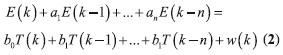
k 表示采樣時刻;
a, b 為方程系數;
n 為差分方程的階次;
E(k), T(K)分別為系統的輸出和輸入序列。
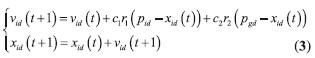
i=1,2,…,N;
d=1,2,…,D;
c1 和c2是非負常數;
r1和r2是介于[0,1]的隨機數;
vid ∈[vmax,vmax ], vmax為粒子最大速度;
t為當前迭代次數。
PSO算法流程圖如圖2所示。PSO算法進行系統辨識,可以看成是一優化過程,適應度函數取如下
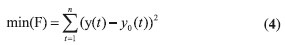
y(t)為模型輸出,min為取適應度函數的最小值。
PSO 算法進行系統辨識是使一組粒子作為模型參數,使式(4)取得最小值,對應的這組粒子就是待求模型參數。

2.2 試驗結果定性分析


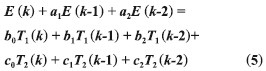

x為工作臺位置,
a、b為線性方程系數。
利用式(6)可以對工作臺左側部分,進行任意位置的縱向熱誤差預測。同理可以建立工作臺右側部分的線性預測模型。



(2)通過粒子群優化算法,能夠根據反饋數據對二階差分模型參數進行實時辨識,使模型能夠跟蹤機床熱誤差的變化,從而使模型保持較高的預測精度。
(3)試驗中發現機床工作臺兩側翹曲現象,通過對銑床工作臺x方向左、中、右三點分別建立熱誤差模型,再通過對三點熱誤差模型各時刻預測值進行分段擬合,實現對工作臺任意位置熱誤差補償。為了對更大尺寸工作臺進行熱誤差補償,只需要按照此原理在工作臺上布置更多的熱誤差傳感器,建立對應點的熱誤差模型,然后對各模型預測值進行分段擬合得到整個工作臺的縱向熱誤差補償模型。為了進一步提高多點模型擬合的精度,可以采用高次多項進行多點擬合。該方法為大尺寸工作臺縱向熱誤差補償提供了一種新思路。